`size_t' is a type suitable for representing the amount
of memory a data object requires, expressed in units of `char'.
It is an integer type (C cannot keep track of fractions of a
`char'), and it is unsigned (negative sizes make no sense).
It is the type of the result of the `sizeof' operator. It is
the type you pass to malloc() and friends to say how much
memory you want. It is the type returned by strlen() to say
how many "significant" characters are in a string.
Each implementation chooses a "real" type like `unsigned
int' or `unsigned long' (or perhaps something else) to be its
`size_t', depending on what makes the most sense. You don't
usually need to worry about what `size_t' looks like "under the
covers;" all you care about is that it is the "right" type for
representing object sizes.
The implementation "publishes" its own choice of `size_t'
in several of the Standard headers: <stdio.h>, <stdlib.h>,
and some others. If you examine one of these headers (most
implementations have some way of doing this), you are likely
to find something like
#ifndef __SIZE_T
#define __SIZE_T
typedef unsigned int size_t;
#endif
This means that on this particular implementation `size_t' is
an `unsigned int'. Other implementations make other choices.
(The preprocessor stuff -- which needn't be in exactly the form
shown here -- ensures that your program will contain only one
`typedef' for `size_t' even if it includes several of the headers
that declare it.)
General guidance: If you want to express the size of something
or the number of characters in something, you should probably use
a `size_t' value to do so. Some people also hold that an array
index is a sort of "proxy" for a size, so `size_t' should be used
for array indices as well; I see merit in the argument but confess
that I usually disregard it.
of memory a data object requires, expressed in units of `char'.
It is an integer type (C cannot keep track of fractions of a
`char'), and it is unsigned (negative sizes make no sense).
It is the type of the result of the `sizeof' operator. It is
the type you pass to malloc() and friends to say how much
memory you want. It is the type returned by strlen() to say
how many "significant" characters are in a string.
Each implementation chooses a "real" type like `unsigned
int' or `unsigned long' (or perhaps something else) to be its
`size_t', depending on what makes the most sense. You don't
usually need to worry about what `size_t' looks like "under the
covers;" all you care about is that it is the "right" type for
representing object sizes.
The implementation "publishes" its own choice of `size_t'
in several of the Standard headers: <stdio.h>, <stdlib.h>,
and some others. If you examine one of these headers (most
implementations have some way of doing this), you are likely
to find something like
#ifndef __SIZE_T
#define __SIZE_T
typedef unsigned int size_t;
#endif
This means that on this particular implementation `size_t' is
an `unsigned int'. Other implementations make other choices.
(The preprocessor stuff -- which needn't be in exactly the form
shown here -- ensures that your program will contain only one
`typedef' for `size_t' even if it includes several of the headers
that declare it.)
General guidance: If you want to express the size of something
or the number of characters in something, you should probably use
a `size_t' value to do so. Some people also hold that an array
index is a sort of "proxy" for a size, so `size_t' should be used
for array indices as well; I see merit in the argument but confess
that I usually disregard it.
 where
where 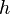 is the depth of the tree.
is the depth of the tree.